基本概念
ClickHouse 是一个开源的列式数据库管理系统,专为大数据量身定做,主要用于在线的分析处理(OLAP)场景。
从定义上看,它更擅长对海量数据进行数据分析处理,没有较强的事务管理能力。而 OLTP通常处理连续不断地事务流,源源不断的修改数据状态。 拿传统的 Mysql 数据库进行对比如下:
- Mysql(OLTP):擅长”增删改”,支持事务,数据以【行】为单位,更加关注写入时每行数据的完整一致性(事务),需要定位到对应的行进行查询,比如查询小明的账号、密码、余额、地址等信息时,数据库会把表中小明这一行的所有数据读入内存。
- ClickHouse(OLAP):擅长海量数据查询,数据以【列】为单位,比如查询指定地址的所有平均余额是多少。
为什么快?
ClickHouse 在进行亿级数据聚合查询时,通过几百毫秒就能得到结果,那么为什么它会这么快呢?主要是因为它根据海量数据选择了不同的数据结构、工程能力进行优化。
在存储层面
数据组织:核心设计
使用列式存储(Columnar Storage)的数据结构:它将同一列的数据在物理磁盘上连续存储。
- 行式存储:在物理存储中,行内不同字段是相邻的
- 列式存储:同列数据在物理存储上相邻,行内其他字段数据存在物理跳跃的情况
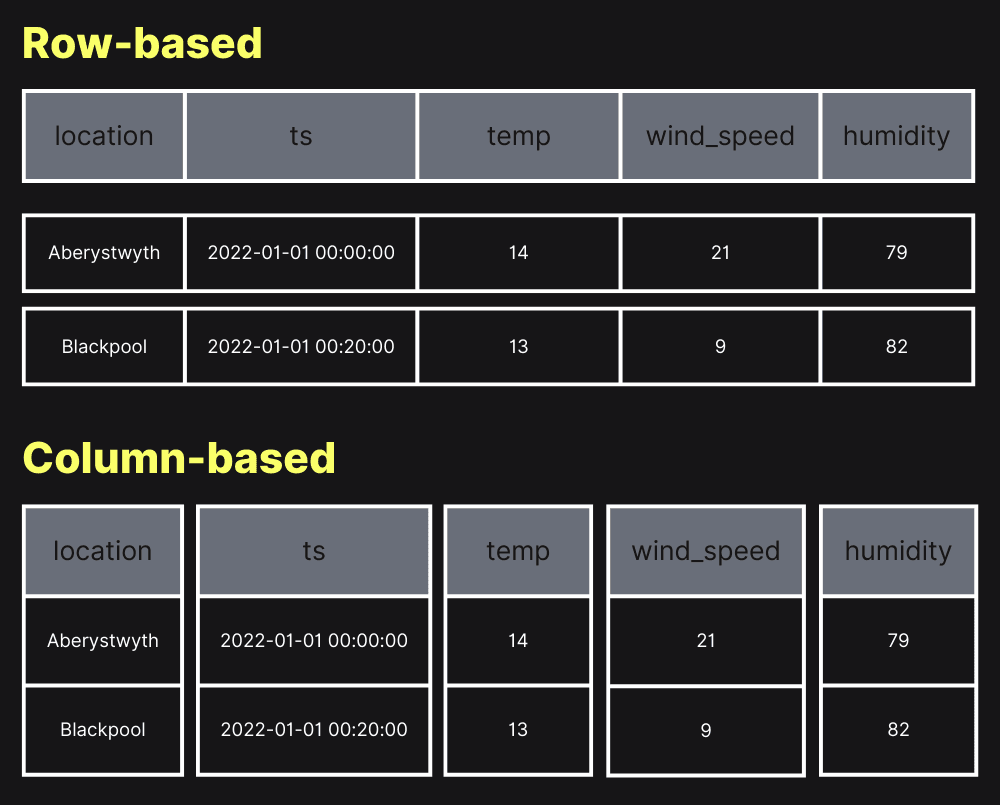
这种结构可以带来两个优势:
- IO 效率高:读取时只需读取关心的列,没有无效读取(较少了无效 IO)
- 压缩效率高:由于相同列的数据格式一致, server 层可以使用高效的压缩算法进行空间压缩 不过,如果需要查询行内全部字段就要付出更高的查询成本了。也就是说只有需要对少量列和大量行的数据进行查询或聚合时,列式存储才会发挥出它的威力。这类数据集通常会有很多列,但是单次查询只会用到其中的几个字段。
数据结构:海量数据插入
为了应对海量数据写入,ck 并没有采用传统数据库常用的 B+ 树,而是借鉴了LSM树,这种树结构把磁盘的随机写入变为顺序写,提供了海量数据写入能力(注意:ck 的海量写入能力指的是单次请求的高吞吐量,而不是请求的高并发数)。 于此同时,ck 中的表由不同的 data part 组成,每次写入请求都会新建一个data part文件夹,也就是说不同的写入请求是相互隔离的,无需锁来保证数据安全。以一次写入四行数据为例:
- 引擎层接收到插入请求后,ck 会在内存中按照主键排序,最终得到一批有序数据。然后每隔一批数据取其主键形成稀疏索引
- 对有序数据按照列进行拆分
- 随后使用压缩算法对每列压缩形成Compressed Block
- 写入磁盘,把压缩后的列作为二进制列文件(.bin)保存在新的 data part 目录中,该目录代表本次insert产生的数据部分。同时稀疏索引(.idx)也会被保存在该目录中
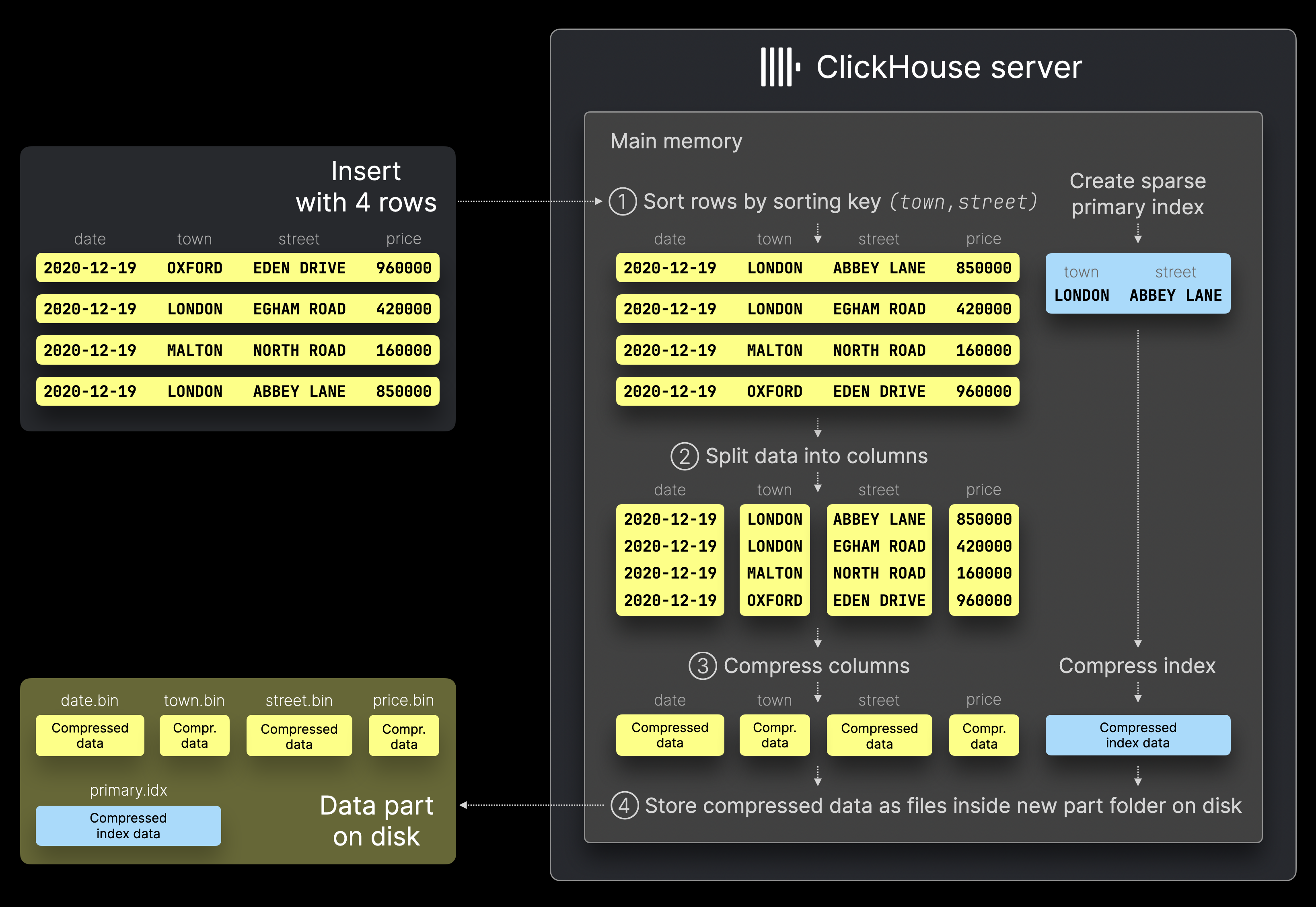 从这里也能看出,ck 更加推荐的是一批次写入大量行,而不是高并发每次请求只有一行。
从这里也能看出,ck 更加推荐的是一批次写入大量行,而不是高并发每次请求只有一行。
注意:磁盘文件生成后是不可变的,后续修改删除并不会修改源文件,而是持续的标记写入,写隔离的方案天然避免了锁竞争,可以为系统带来更大的吞吐能力。
合并:前置计算
data part 数量过多会影响查询性能,因此 ck 使用后台线程对 data part 进行合并,合并线程会异步的把较小的 data part 合并成更大的,直到它们到达指定的文件大小。
初始写入时文件层级为 0,层级会随着 data part 发生的合并次数进行递增。发生过合并操作的文件会被标记为非活跃,并在一段时间后被ck 删除。
在合并的过程中,ck 会把常用的聚合函数进行计算,这样提前计算能够减少查询真正到来时的耗时。随着时间推移,最终会形成一个由合并 part 形成的树
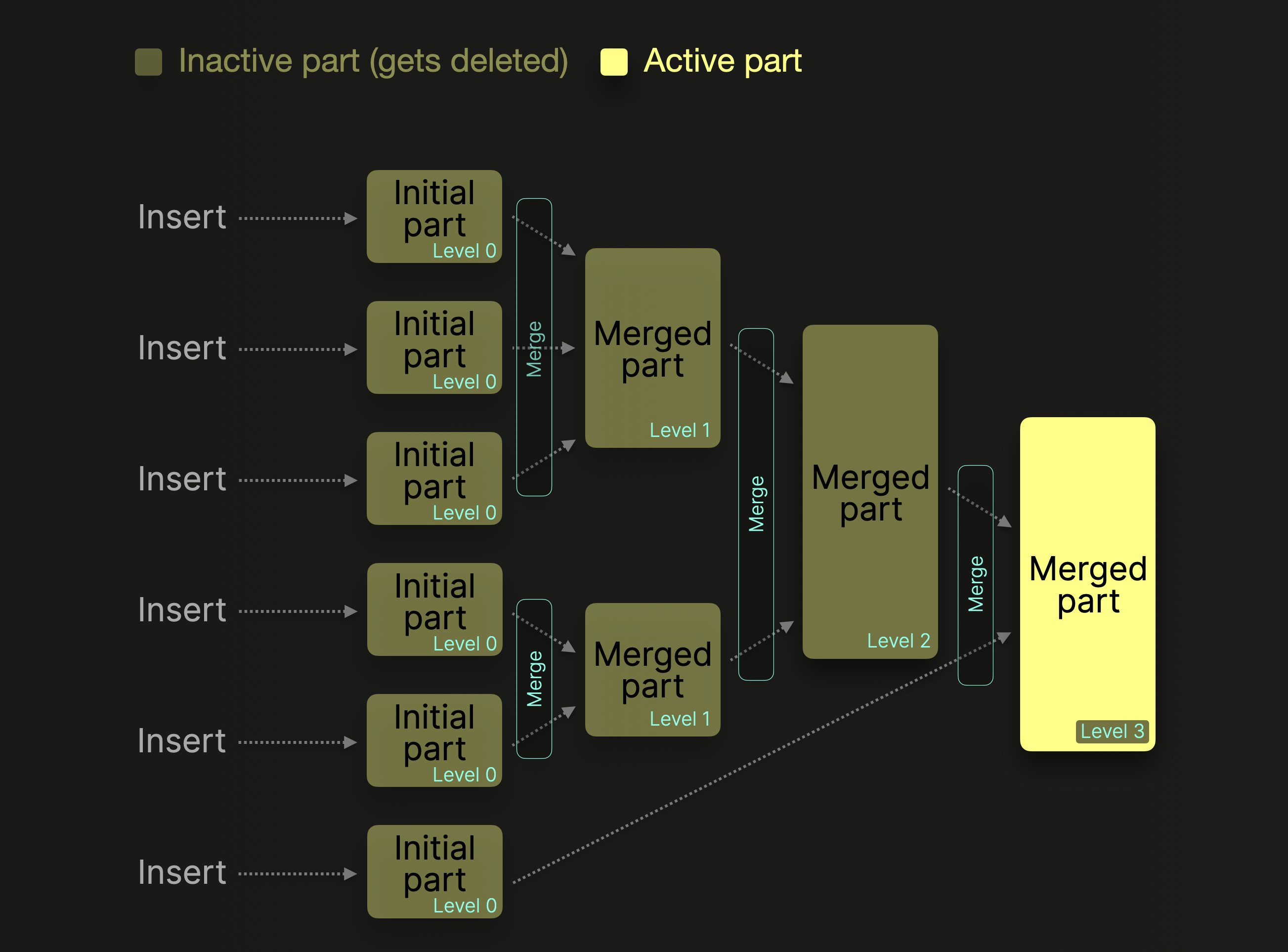 请注意,ck 的合并不是为了建立一棵查找树,这和RocksDB有本质区别。ck 在发生查询时并不会按照层级进行遍历:
请注意,ck 的合并不是为了建立一棵查找树,这和RocksDB有本质区别。ck 在发生查询时并不会按照层级进行遍历:
- 根据 sql 中的 where 条件,首先对分区进行过滤,无关的时间分区 part 会被直接过滤掉
- 查询引擎会拿到当前所有的 active part,无论当前 part 处于哪个层级
- 检查 data part 下的索引文件来判断是否需要查询当前数据
- 定位到需要查询数据后把稀疏索引加载到内存进行二分查找,此时能够拿到一个数据区间
- 接着根据位置映射文件拿到磁盘偏移量进行最后数据的读取
在引擎层方面
由于列式存储的结构,CPU 缓存可以一次拿到更多有效数据,同时由于数据在物理上是连续且一致的,ck 针对不同硬件架构编写了不同的 SIMD 指令。该指令可以让 CPU 进行向量化计算,在一次执行周期内同时处理多条数据。相比于传统数据库的单条处理,向量化计算自然而然可以实现更高的性能。
分布式设计
分布式系统是为了解决两个核心问题:
- 高性能,通常用分片来解决横向扩展问题,需要注意分片规则
- 高可用,通常用副本机制来解决可用性问题,需要注意副本间数据一致性 ck 在实现这两个核心能力上有所不同。
分片维度
ck 提供了分布式表的能力,简单来说该表就像一个代理,并不会保存数据,而是接受所有请求并按照分片键转发到对应的分片上。在海量数据场景极易出现单点效应,建议在应用层计算后直接写入对应的物理表。
副本维度
ck 并没有采用传统的主从架构,而是采用了多主架构,具体来说就是一次写入请求的数据最终会保存到对应分片下的所有副本。这样设计具有以下几个好处:
- 节省了选主时间,同时避免主节点的单点效应,写入性能更加强悍
- 多主架构具有天然的异地多活能力,能够根据 IP 地址或者负载压力选择更合适的机器 这也带来了一个显著弱点:节点挂掉或者节点数据同步出现数据不一致时,会导致查询不到数据,从这点来看,ck 选择了可用性 + 分区容错性,牺牲了强一致性。 ck 在处理一次写入请求时,步骤如下:
- 单点落盘,客户端请求结束。数据在节点磁盘成功保存后,如果没有进行多副本节点设置,直接返回成功。
- 元数据同步。随后节点生成一条日志并通知 zk,此时其他主节点会收到该通知消息。
- 物理文件同步。zk 日志并不会保存原始文件,其他节点会与写入节点建立连接,并直接拉取原物理文件,减轻 zk 负载